A self-organizing approach to detection of moving patterns for real-time applications
Lucia Maddalena, ICAR-CNR, Naples Branch
Alfredo Petrosino, University Parthenope of Naples
This page has been created in order to show results of moving object detection using algorithm HSV-SO presented in
[1] on different image sequences, and to compare them with those obtained with other existing algorithms.
1. Sequence MSA
Size: 320*240
Source: home-made
We report two consecutive sequence frames (Previous and Actual frames) and the actual frame with corresponding moving
object detection mask computed with HSV-SO algorithm. The detection mask shows that the walking man is
perfectly detected. Moreover the bag, which has been left by the man in previous frames, is still detected as an object extraneous
to the background. A layering approach (not yet introduced in our system) could help the algorithm to signal the bag as a stopped
object.
We also show the background model computed by the HSV-SO algorithm and its change mask from previous frame.
We would remark that the background model is represented by a neuronal map whose size is 9 times greater
than that of the original image. In the reported figures they appear to have the same size only for an
easier comparison. We can observe that the background model is a quite accurate (enlarged) representation of the real background.
Small differences with the real background can be noticed only in few pixels near the column; these are due to a previous passage of
the man in front of the column and the consequent only partial update of the corresponding background pixels.
| Previous frame | Actual frame | Actual frame with moving object detection mask | Background model |
Background model change mask from previous frame |
 |
 |
 |
 |
 |
Shadow suppression algorithms, such as the one described in [2], are readily inserted into
HSV-SO background subtraction and update algorithm, having care of not updating the neuronal map for background pixels detected
as shadows. An example is here reported:
| Without shadow removal | With shadow removal |
 |
 |
2. Sequence Walk1
Size: 384*288
Source: [3], filename: Walk1
We report two consecutive sequence frames (Previous and Actual frames) and the actual frame with corresponding moving
object detection mask computed with HSV-SO algorithm. The man in the center of the room is perfectly detected, even
though some parts of the man (such as the arm) tend to camouflage with the pavement and could have led to a partial detection. The
group of persons lying close to the lower left side of the image (in the reflection on the pavement of the light coming through the
windows) is partially detected. This is reasonable since such persons are barely distinguishable also for the human eye. Same
observations hold for the person lying close to the plant in lower center side of the image.
We also show the background model computed by the HSV-SO algorithm and its change mask from previous frame.
We can observe that the background model is a quite accurate (enlarged) representation of the real background.
The change mask of the background model shows clearly that wide areas of constant intense white (in the reflection on the
pavement of the light coming through the windows) are not updated from previous frame.
| Previous frame | Actual frame | Actual frame with moving object detection mask | Background model |
Background model change mask from previous frame |
 |
 |
 |
 |
 |
3. Wallflower Test Images
Size: 160*120
Source: [4], filenames: Camouflage, TimeOfDay, WavingTrees
The three image sequences represent some of the canonical problems for background subtraction highlighted in
[4]. For each of them we show the first image of the sequence,
the image in the sequence at which the comparison was done,
the hand-segmented images of the foreground used as ground truth for comparison, and the foreground masks obtained
with:
1) HSV-SO algorithm, described in [1];
2) Pfinder algorithm: the background model assumes that the intensity values of a pixel can
be modeled by a Gaussian distribution [5];
3) VSAM algorithm: implements the approach proposed in
[6], based on the integration of pixel analysis and
region analysis modules to extract motion by a finite state
machine. It is able to recognize when objects have stopped and to disambiguate
overlapping objects;
4) CB algorithm: vector quantization is used to incrementally construct a codebook in order to generate a
background/foreground model [7].
Results of the CB algorithm have been obtained using the software provided by the authors.
For all considered algorithms we experimented with different settings of adjustable parameters until the result
seemed optimal over the entire sequence.
Finally, for each algorithm we report Recall and Precision measures, where
Recall = (number of true foreground pixels detected)/(number of foreground pixels in the ground truth),
Precision = (number of true foreground pixels detected)/(number of foreground pixels detected).
and we report also the F-measure (harmonic mean of Recall and Precision):
Fmeasure = 2*(Recall*Precision)/(Recall+Precision).
| |
Camouflage |
TimeOfDay |
WavingTrees |
| First image of the sequence |
 |
 |
 |
| Test Image |
 |
 |
 |
| Description | Foreground covers monitor pattern | Light gradually brightened | Tree waving |
| Ideal foreground |
 |
 |
 |
| Foreground with HSV-SO algorithm |
 |
 |
 |
| |
Recall=0.9094 Precision=0.9834 Fmeasure=0.9450 |
Recall=0.7637 Precision=0.8804 Fmeasure=0.8179 |
Recall=0.9858 Precision=0.9712 Fmeasure=0.9784 |
| Foreground with Pfinder algorithm |
 |
 |
 |
| |
Recall=0.9553 Precision=0.9830 Fmeasure=0.9689 |
Recall=0.5021 Precision=0.9852 Fmeasure=0.6652 |
Recall=0.9922 Precision=0.6952 Fmeasure=0.8176 |
| Foreground with VSAM algorithm |
 |
 |
 |
| |
Recall=0.9487 Precision=0.9796 Fmeasure=0.9639 |
Recall=0.4993 Precision=0.9878 Fmeasure=0.6633 |
Recall=0.9947 Precision=0.9552 Fmeasure=0.9745 |
| Foreground with CB algorithm |
 |
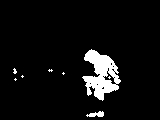 |
 |
| |
Recall=0.9700 Precision=0.9893 Fmeasure=0.9796 |
Recall=0.7198 Precision=0.9450 Fmeasure=0.8172 |
Recall=0.9727 Precision=0.9670 Fmeasure=0.9698 |
References
[1]
L. Maddalena and A. Petrosino, A self-organizing approach to detection of moving patterns for real-time applications,
accepted at BVAI'07,
http://clava.cib.na.cnr.it/BVAI2007/
[2]
Cucchiara, R., Piccardi, M., Prati, A.:
Detecting Moving Objects, Ghosts, and Shadows in Video Streams,
IEEE Transactions on Pattern Analysis and Machine Intelligence (2003), 25(10), 1--6
[3]
CAVIAR Project, IST 2001 37540, CAVIAR Test Case Scenarios,
http://groups.inf.ed.ac.uk/vision/CAVIAR/CAVIARDATA1/
[4]
Test images for the paper:
K. Toyama, J. Krumm, B. Brumitt, B. Meyers,
Wallflower: Principles and Practice of Background Maintenance,
Seventh International Conference on Computer Vision, September 1999, Kerkyra, Greece, pp. 255-261, IEEE Computer Society Press.
http://research.microsoft.com/users/jckrumm/WallFlower/TestImages.htm
[5]
Wren, C., Azarbayejani, A., Darrell, T., Pentland, A.:
Pfinder: Real-Time Tracking of the Human Body, IEEE Trans. on PAMI (1997),
{\bf 19} 7, 780--785.
[6]
Collins, R.T., Lipton, A.J., Kanade, T., Fujiyoshi, H., Duggins,
D., Tsin, Y., Tolliver, D., Enomoto, N., Hasegawa, O., Burt, P.,
Wixson, L.:
A System for Video Surveillance and Monitoring, The
Robotics Institute, Carnegie Mellon University (2000),
CMU-RI-TR-00-12.
[7]
Kim, K., Chalidabhongse, T.H., Harwood, D., Davis, L.S.:
Real-time Foreground-background Segmentation using Codebook Model,
Real-Time Imaging (2005), 11, 172-185.